C++ requires many algorithms to be implemented in amortized constant time. I was curious about what this meant for vector insertion. To get started I first wrote an article about amortized time in general. Now I’d like to apply that to appending vector items.
23.3.6.1-1 A vector is a sequence container that supports random access iterators. In addition, it supports (amortized) constant time insert and erase operations at the end;
In this analysis I’m looking at end insertion, which is done with the C++ vector::push_back function.
Cost of copying
Complexity analysis is usually based on counting how many times a dominant operation occurs. Often we count the number of comparisons, such as with trees, but that doesn’t make sense for a vector insert.
What should we count? Maybe we should include memory allocation, or is that done in constant time? Do we need to consider a specific cost model, such as a “random-access machine”? The C++ standard only gives us this description:
23.2.1-1 All of the complexity requirements in this Clause are stated solely in terms of the number of operations on the contained objects. [ Example: the copy constructor of type vector <vector > has linear complexity, even though the complexity of copying each contained vector is itself linear. — end example ]
Let’s focus on the cost of copying data, this should be okay by that definition. For common use, this is the most interesting cost since it is usually the highest cost.
Given a type T we define the cost of an operation as the number of times an object of type T is copied. Each time an item is copied, it costs 1.
What is a vector?
It’s helpful to know what a vector actually is. It has a current number of items, its size, and capacity to store more. The requirements also state:
The elements of a vector are stored contiguously, meaning that if v is a vector … then it obeys the identity &v[n] == &v[0] + n for all 0 <= n < v.size().
We can use this pseudo-structure to represent the vector:
vector { T* store int size int capacity }
capacity is the total space available in store. size is the current number of items in store that are actually defined. The remaining are undefined memory.
Two insertion scenarios
When we insert a new item into a vector, one of two things can happen:
size < capacity: The item is copied tostore[size]andsizeis incremented. That’s one copy: a cost of1.size == capacity: New space must be allocated first. The old items must be copied to the new store. Then the new item added. We copy once for each existing item, plus once for the new item: a cost ofsize + 1.
That second cost is clearly linear, not the constant time the standard requires.
This where the amortized cost comes in. We aren’t interested in the worst case, but the average case. As the vector reserves capacity beyond its current size, we don’t always have to resize the vector to add a new item. The amortized cost is the average cost of many insertions.
There must be some way to make this cost be constant time.
How many resizes
Let’s first try the approach of increasing the capacity by 








Operation 

Reducing to a single closed form equation that gives us:

We need a form related to 


To get the amortized cost we divide by the total number of operations:

Strip out the constants, and we’re left with an amortized cost of 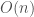
Geometric size
Let’s move on to another option for resizing: start with 1 capacity and double each resize. Let 

Basic geometric series reduce very nicely:

At this point we could swallow the cost of 1 copy and drop the
part. Given the exponential term before it, the constant 1 isn’t relevant. For thoroughness, I’ll leave it in.
Relate back to 

Divide by

The constant 3 is the most significant term, so our amortized cost of insert is 
The intuitive solution
That 3 represents a concrete number of operations: how many times each item will be copied. It could have been 2 or 4 and still been constant time. Indeed, if we were off by 1 in our definition of 
What are those 3 copies? The first copy is clear: when you first insert an element it has to be copied into the store memory. That leaves us with two copies.
Think of the structure of store at the moment a resize happens. It starts with size == capacity, it’s full, that’s why it’s being resized. After resize it ends up at size == capacity/2 as the capacity has doubled. The second half of the store is empty.
This second half will eventually be filled, and once filled, all items have to be copied somewhere new. This means that for each item inserted, 2 copies happen. The item itself will need to be copied somewhere new, as well as one item from the first half. This relation holds regardless of how many resizes have been done. Each resize always results in one full and one empty half.
If we think in terms of the accounting method that means insertion costs 3 credits. The first credit pays for its immediate insertion. The second credit pays for it’s eventual copy to a new store. The third credit pays for copying an existing item to the new store. The doubling in capacity each resize ensures these new items always have enough credits to cover the copying cost.

